El problema que nadie había resuelto bien
El “vibe coding” llegó para quedarse. Millones de developers hoy escriben código describiendo en lenguaje natural lo que quieren, y una IA lo genera en segundos. El resultado: más código, más rápido, pero también más bugs sutiles, estructuras que nadie entiende del todo y vulnerabilidades de seguridad que se cuelan sin que nadie las detecte.
El cuello de botella ya no es generar código — es revisarlo. Y ese es exactamente el problema que Anthropic decidió atacar.
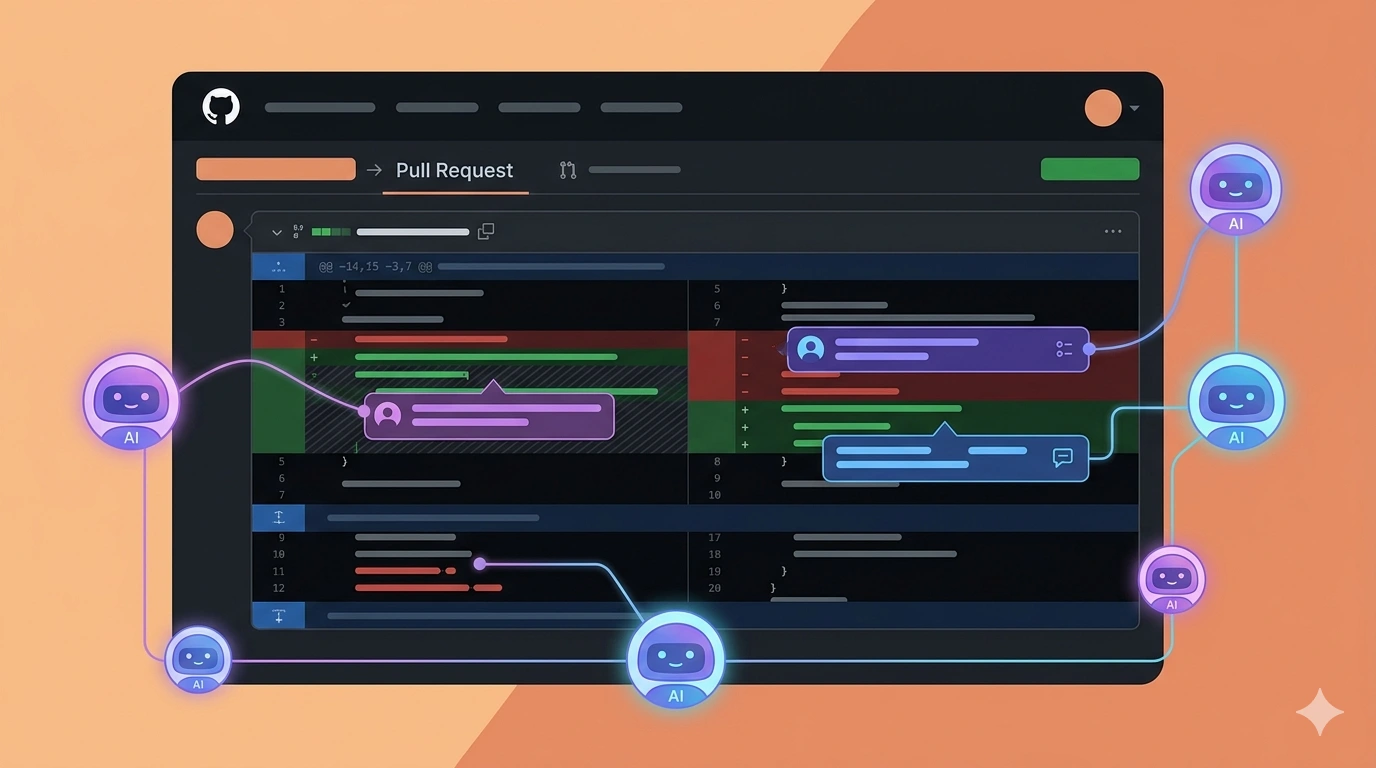
El pasado lunes 9 de marzo de 2026, Anthropic lanzó Code Review dentro de Claude Code: un sistema multi-agente que analiza automáticamente cada pull request en busca de errores lógicos, bugs y vulnerabilidades, y deja comentarios inline directamente en GitHub.
Los números que lo justifican
Antes de entrar en cómo funciona, vale la pena entender el contexto con datos reales:
El output de código por developer en Anthropic creció un 200% en el último año, desbordando los pipelines de revisión tradicionales. Antes de implementar su propio sistema de revisión por IA, solo el 16% de los cambios de código recibían comentarios sustanciales en su revisión. Tras implementarlo internamente, ese porcentaje subió al 54%.
Claude Code’s run-rate revenue ha superado los $2.5B desde su lanzamiento, y las suscripciones enterprise se han cuadruplicado desde el inicio del año.
La demanda era real y venía del mercado, no de una decisión interna de producto. Cat Wu, Head of Product de Anthropic, lo explicó con claridad: los enterprise leaders preguntaban constantemente cómo asegurarse de que los pull requests que Claude Code genera sean revisados de forma eficiente.
Cómo funciona Code Review
Arquitectura multi-agente
Code Review emplea una arquitectura multi-agente donde múltiples agentes de IA examinan el código desde distintos ángulos, agregan los hallazgos, eliminan duplicados y priorizan los problemas con un sistema de severidad por colores: rojo para crítico, amarillo para revisar, y morado para problemas históricos.
La profundidad del análisis es adaptativa: cuanto más complejo es el PR, más agentes se despliegan y más profundo es el análisis. Los cambios más triviales reciben un análisis más ligero.
Integración con GitHub sin configuración
Para los developers no hay configuración requerida — el sistema arranca automáticamente cada vez que se abre un PR. Los admins deben habilitar Code Review en la configuración de Claude Code, instalar la GitHub App y seleccionar los repositorios donde quieren que corra.
El flujo completo es así:
Developer abre PR en GitHub
↓
Code Review se dispara automáticamente
↓
Múltiples agentes analizan el código en paralelo
↓
Se agregan hallazgos y se eliminan falsos positivos
↓
Se rankean por severidad (crítico / revisar / histórico)
↓
Comentarios inline aparecen directamente en el PR
↓
Developer revisa, acepta o descarta cada hallazgo
↓
Merge sigue siendo decisión humana — siempreFoco en errores lógicos, no en estilo
Esta es una decisión de diseño deliberada y muy acertada. Cat Wu fue explícita sobre esto: decidieron enfocarse puramente en errores lógicos para capturar las cosas de mayor prioridad. Los developers se irritan cuando el feedback automatizado no es inmediatamente accionable — este foco garantiza que cada comentario valga la pena.
Lo que Code Review sí detecta:
- Bugs lógicos que pasarían un code review humano rápido
- Errores de tipado y type mismatches
- Vulnerabilidades de seguridad (análisis ligero incluido, análisis profundo vía Claude Code Security)
- Problemas de autenticación y autorización
- Race conditions y problemas de concurrencia
Lo que Code Review no hace:
- Revisar estilo de código (eso es para linters y formatters)
- Aprobar PRs de forma autónoma — esa decisión siempre es humana
- Reemplazar completamente la revisión humana en código crítico
Casos reales documentados por Anthropic
En una prueba interna, Code Review detectó un cambio de una sola línea de aspecto inocente en un servicio de producción que habría roto el mecanismo de autenticación del servicio. Se corrigió antes del merge, y el engineer reconoció después que no lo habría detectado por su cuenta.
En el caso de TrueNAS, durante una refactorización de cifrado ZFS para su middleware open-source, el sistema de revisión detectó un bug en código adyacente que arriesgaba un type mismatch que borraría el cache de claves de cifrado durante una operación de sincronización.
En un piloto con Mozilla Firefox, Claude Opus 4.6 escaneó el enorme codebase del navegador en apenas dos semanas y detectó 22 vulnerabilidades.
El razonamiento agéntico detrás
A diferencia de las herramientas SAST tradicionales que se basan en pattern matching rígido, Claude Code opera como un agente stateful. Según los últimos benchmarks internos de Anthropic, el modelo puede encadenar un promedio de 21.2 tool calls independientes — editar archivos, ejecutar comandos en terminal, navegar directorios — sin intervención humana. Eso representa un aumento del 116% en autonomía en los últimos seis meses.
Esto significa que el sistema no analiza un archivo en aislamiento: razona a través de todo el repositorio. Usa el archivo CLAUDE.md — una especie de manual para la IA — para entender las convenciones específicas del proyecto, las dependencias del pipeline de datos y las particularidades de infraestructura.
Disponibilidad y precio
Code Review está disponible en research preview para clientes de Claude for Teams y Claude for Enterprise. Está dirigido a empresas de gran escala que ya usan Claude Code, como Uber, Salesforce y Accenture.
Los reviews se facturan por uso de tokens. El costo varía según la complejidad del PR, con un promedio estimado de $15 a $25 por review. La duración promedio de un review es aproximadamente 20 minutos.
Un dato importante para calibrar el valor: la pregunta real que hace The Register es si pagar $60/hora a un developer humano para hacer el mismo review produciría resultados comparables o mejores. La respuesta no es simple — depende del tipo de código y del nivel del reviewer. Pero para equipos donde un solo bug en producción puede costar mucho más que $25, la ecuación se inclina rápidamente a favor de la herramienta.
El contexto más amplio: un día histórico para Anthropic
El lanzamiento de Code Review no ocurrió en un día cualquiera. El mismo 9 de marzo, Anthropic presentó dos demandas legales contra el Departamento de Defensa de EE.UU. por designarla como riesgo en la cadena de suministro nacional, mientras que Microsoft anunció simultáneamente una nueva alianza integrando Claude en Microsoft 365 Copilot a través de un producto llamado Copilot Cowork.
La designación como riesgo de seguridad provino de una negociación fallida: el Pentágono quería acceso irrestricto a Claude para “todos los propósitos legales”, mientras Anthropic estableció dos líneas rojas: que su IA no sería usada para armas autónomas ni para vigilancia doméstica masiva. Cuando las negociaciones colapsaron, el presidente Trump instruyó a todas las agencias federales a dejar de usar tecnología de Anthropic.
Para un blog de developers, el contexto importa: la empresa que construyó la herramienta de revisión de código más sofisticada del mercado está simultáneamente en el centro de uno de los debates más importantes sobre los límites del uso de IA en defensa y seguridad nacional.
¿Qué significa esto para el flujo de trabajo de un developer?
El impacto más real no es que “la IA revise código” — eso ya lo hacía Copilot, Coderabbit y otros. El impacto real es la arquitectura multi-agente y el razonamiento a nivel de repositorio.
Herramientas anteriores analizaban un archivo o una función en aislamiento. Code Review razona sobre el sistema completo: entiende las dependencias, el contexto del proyecto y el impacto de un cambio en otras partes del código. Eso es un salto cualitativo, no una mejora incremental.
Para developers que ya usan Claude Code en el día a día, el mensaje es claro: el cuello de botella que estaban experimentando con los PRs tiene ahora una solución nativa dentro de la misma herramienta. Para los que aún no usan Claude Code en equipos, este lanzamiento hace que la propuesta de valor sea mucho más concreta.
Conclusión
Code Review no es el primer tool de revisión de código asistida por IA, pero sí el primero con una arquitectura multi-agente que razona a nivel de repositorio completo, integración nativa con el flujo de GitHub y un foco deliberado en errores de alto impacto sobre ruido de estilo.
Los números internos de Anthropic — de 16% a 54% de PRs con revisión sustancial — son el mejor argumento de venta. Si esos resultados se replican en otras organizaciones, el caso de adopción enterprise se construye solo.
El código sigue siendo responsabilidad humana. Pero el primer filtro de calidad ya no tiene que serlo.
Fuentes
-
Anthropic launches code review tool to check flood of AI-generated code
— TechCrunch, 9 de marzo 2026 -
Anthropic brings code review into Claude Code
— SD Times, 9 de marzo 2026 -
Anthropic debuts Code Review for teams, enterprises
— The Register, 9 de marzo 2026 -
Anthropic rolls out Code Review as it sues over Pentagon blacklist
— VentureBeat, 9 de marzo 2026 -
Anthropic Claude Code Review: Parallel AI Agents for Bugs & Security
— WinBuzzer, 10 de marzo 2026
Tags
¿Te fue útil este artículo?
Puedes apoyar mi trabajo invitándome un café.


